- Published on
Ollama Models via API
- Authors

- Name
- Marek Zebrowski
- @zebrowskidev
Exposing Ollama models with an API
Summary
This blog post is focused on creating an API that other apps can consume to interact with our Ollama models. Doing this will allow virtually any app to consume the models hosted in Ollama.
Using FastAPI provides benefits over just using the Ollama API such as security, customization and platform maturity.
Ollama API vs FastAPI
Ollama has a good built-in API that allows developers to take full advantage of its features. This built-in API is great for development and home-lab use cases but has limitations when deployed to a business environment. FastAPI would require the creation of a separate API inherently using more resources however it's a more mature platform that is more secure along with a large community of users making it much easier to find forums or articles about the issue you are experiencing
More information on the built-in Ollama API is available here
What is FastAPI?
FastAPI has quickly become one of the go-to frameworks for building APIs in Python. Aside from being a lightweight option, it boasts speed and ease of use as strong perks. FastAPI is my go-to for setting up a quick API and suits Ollama well. FastAPI is also very easy to deploy from local servers to the cloud in a docker container.
How it works?
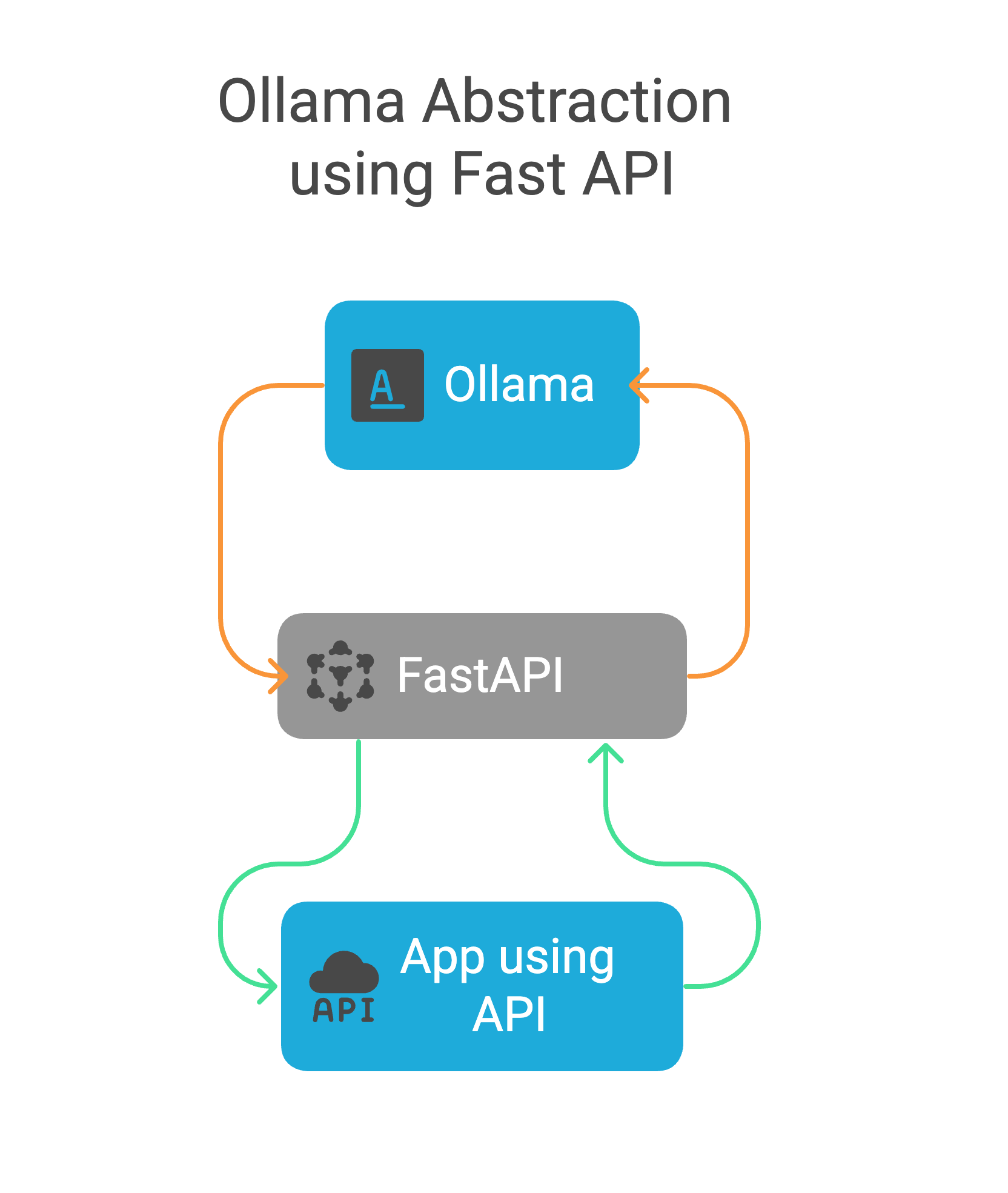
Ollama has Python library that allows a Python app to interact with models. Using FastAPI we can allow other apps and even apps in other programing languages that Ollama doesnt support acecess to the models we have created.
Take a step back and look at what this means in practice. If a user is in an app that needs AI, it would call the fastAPI with a GET request. Once the fastAPI gets the request it will use the Ollama Python library call to Ollama. Ollama will then send the request to the model so it can process it and give output. Once the model is done, the output goes to Ollama and then out via the Ollama library. Once the API receives it, it will send it back in a web response.
Architecture Diagram
Setting Up FastAPI
Before writing all the code, make sure you can run a 'hello, World' verion to confirm your Python enviroment is configured correctly to save any headaches not related to your code later.
- Installing Packages
First, you need to install FastAPI, Uvicorn (the ASGI server used to run your FastAPI app), the Ollama Library, and pydantic for passing data. To do this, run the following command in your terminal:
pip install fastapi uvicorn ollama pydantic
- Create a Py File
let’s create a Python file where you'll define your FastAPI app. Let’s call it main.py.
from fastapi import FastAPI
# Instance of the FastAPI class
app = FastAPI()
# A GET request on the default path
@app.get("/")
def read_root():
return {"message": "Hello, World!"}
- Running the API Unvicorn is the webserver we will use host the API. Notice
mainmatches the name of the.pyfile.appmatches the name of the variable assigned inapp = FastAPI(). The--reloadflag tells uvicorn to automatically reload the app whenever a change is made.
uvicorn main:app --reload
- Calling the API This can be done
curl http://localhost:8000
FastAPI supports automatic documentation. For more basic commands you can call the endpoints using "Try it out" in SwaggerDocs.
- Swagger docs style: http://127.0.0.1:8000/docs
- ReDocs style : http://127.0.0.1:8000/redoc
TIP
cURL & Docs page works but testing but I recommend Postman. This is super helpful especially later in development.
- Adding the Ollama Library
from fastapi import FastAPI
import ollama
app = FastAPI()
# The model parameter is the model name that you want to use.
model = 'deepseek-r1:1.5b'
@app.get("/")
def read_root():
return {"message": "Hello, World!"}
@app.get("/ollama/{prompt}")
def ollama_response(prompt: str):
"""
Endpoint to interact with Ollama.
"""
try:
response = ollama.chat(model=model, messages=[
{
'role': 'user',
'content': prompt,
},
])
return {"response": response['message']['content']}
except Exception as e:
return {"error": str(e)}
#Notice the async keyword in the function definition.
#This is because the function is asynchronous.
@app.get("/ollama_generate/{prompt}")
async def ollama_generate(prompt:str):
"""
Endpoint for text completion with ollama
"""
try:
response = ollama.generate(model=model, prompt = prompt)
return {"response": response['response']}
except Exception as e:
return {"error": str(e)}
Calling the API using cURL
curl -X 'GET' \
'http://127.0.0.1:8000/ollama/Who%20are%20you%3F' \
-H 'accept: application/json'
result:
{"response":"<think>\n\n</think>\n\nGreetings! I'm DeepSeek-R1, an artificial intelligence assistant created by DeepSeek. I'm at your service and would be delighted to assist you with any inquiries or tasks you may have."}%
Notice that these two endpoints have two different methods they call ollama.generate() and ollama.chat(). While these may sound similar and work similar provided this basic example, they have different purposes.
ollama.generate()
This is the endpoint to generate a single response to the prompt. Unlike the chat method, this does not take any previous context from the user's past prompts. The power of the generated endpoint is the customization of responses and response speed. You can create a custom response format and pass that to the model to return data in a format other systems can interpret such as JSON. Expanding on the previous code to adding a POST endpoint and changing to passing data via the request body.
from fastapi import FastAPI
from pydantic import BaseModel
import ollama
app = FastAPI()
# The model parameter is the model name that you want to use.
model = 'deepseek-r1:1.5b'
class DataInBody(BaseModel):
prompt: str
format: object
options: object
@app.get("/")
def read_root():
return {"message": "Hello, World!"}
@app.get("/ollama/{prompt}")
def ollama_response(prompt: str):
"""
Endpoint to interact with Ollama.
"""
try:
response = ollama.chat(model=model, messages=[
{
'role': 'user',
'content': prompt,
},
])
return {"response": response['message']['content']}
except Exception as e:
return {"error": str(e)}
#Notice the async keyword in the function definition. This is because the function is asynchronous.
@app.get("/ollama_generate/{prompt}")
async def ollama_generate(prompt:str):
"""
Endpoint for text completion with ollama
"""
try:
response = ollama.generate(model=model, prompt = prompt, format="json")
return {"response": response['response']}
except Exception as e:
return {"error": str(e)}
#Notice 'app.post' instead of 'app.get'
@app.post("/ollama_generate/")
async def ollama_generate(data :DataInBody):
"""
Endpoint for text completion with ollama, using POST method
"""
try:
response = ollama.generate(model=model, prompt = data.prompt, stream= False, format=data.format)
return {"response": response['response']}
except Exception as e:
return {"error": str(e)}
curl -X 'POST' \
'http://127.0.0.1:8000/ollama_generate/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "What is the mass of the sun? Use Json",
"format": {
"type": "object",
"properties": {
"mass": {
"type": "integer"
},
"volume": {
"type": "integer"
}
},
"required": [
"mass",
"volume"
]
},
"options": {
"temperature": 0
}
}'
result:
{
"response": "{\"mass\": 63, \"volume\": 8727507949346781}"
}
ollama.chat()
The chat method allows for a chat history to be fed into the model. This is useful for chatbots or AI assistants running inside another application such as a web form or business report. This allows the user to ask questions have a chat and for the model to maintain consistency. Using this functionality just requires the creation of an object to hold a list of messages.
class Message(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
messages: list
@app.post("/ollama_chat/")
async def ollama_response(chat_request: ChatRequest):
"""
Endpoint to interact with Ollama, using POST method
"""
try:
messages_dict = []
for message in chat_request.messages:
messages_dict.append(message)
response = ollama.chat(model=model, messages=messages_dict)
return {"response": response['message']['content']}
except Exception as e:
return {"error": str(e)}
curl -X 'POST' \
'http://127.0.0.1:8000/ollama_chat/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"role": "user",
"content": "What is heavier 1000lbs of feathers or iron?"
},
{
"role": "assistant",
"content": "A single piece of iron weighs more than 1000 pounds."
},
{
"role": "user",
"content": "What about steel?"
}
]
}'
result:
{
"response": "<think>\nOkay, let's see what the user just asked. They previously asked which was heavier: 1000lbs of feathers or iron. I answered that 1000lbs is way more than a single iron piece, since iron can weigh much more per unit volume.\n\nNow they're asking about steel next. So they probably want to compare iron and steel against each other in terms of weight. \n\nI need to make sure my response is clear and accurate. First, I'll note that both steel and iron are dense materials, so 1000lbs of them should be similar. But since the user mentioned \"steel,\" maybe they're thinking about different quantities.\n\nI should clarify whether it's per unit volume or per weight. They might not know if you can weigh just a piece of steel easily. So explaining that both have high density is important to avoid confusion.\n\nThey could be curious about how much they actually need to weigh to get 1000lbs in each, maybe for a project or something. I should mention the difference between volume and weight here.\n\nAlso, perhaps they're trying to figure out which material can hold more without breaking, so mentioning that they’re essentially equivalent makes sense. Maybe offer some examples of everyday items to help them visualize it better.\n\nOverall, my response needs to be clear, explain both materials thoroughly, point out their density similarities, and maybe give a practical example to make the concept clearer.\n</think>\n\nIn terms of weight, **both steel and iron** have very high densities, which means that 1000 lbs of each would actually be equivalent. However, if you're considering how much \"weight\" you need to achieve in each material, they're not necessarily directly comparable unless you specify the volume or size.\n\nFor example:\n\n- A single piece of steel (even a small one) can weigh thousands of pounds depending on its volume.\n- Similarly, a single iron piece could also weigh thousands of pounds based on its size and thickness.\n\nSince both materials have similar densities, 1000 lbs of steel would be roughly the same as 1000 lbs of iron in terms of weight. However, they can hold different amounts of mass or volume without significantly affecting their overall density."
}
The response can be limited using options like in the generate method. In the chat it is the clients job to maintain chat history and pass it back to the model with each API call.
Best Practices
Before sending your newly created API to QA(Quality Assurance) or UAT(User Acceptance Testing) to ship an AI project there are some considerations. The new wave of AI riding on the backs of LLMs is exciting but it is still a novel technology. Getting an MVP ( minimal viable product) to market is critical but doing it the wrong way can be devastating and costly both in resource costs and litigation should security be ignored. These questions serve to guide thought in the right direction being based on my own experiences. This is not a complete preflight checklist, you don't need to check off each question as one size does not fit all especially in the tech world.
- Is the underlying model “production ready”?
- Does the model still frequently hallucinate?
- Is the model returning the correct format?
- Is the model overly “chatty"?
- Is this setup performant and efficient?
- Are there canned answers to frequent questions that the model should generate for certain prompts? Can you generate seeds for these and store them in an in-memory database or table?
- Have you embraced concurrency and async operations?
- Is the business logic bloated with I/O or resource-intensive operations that do not need to occur before the API responses?
- Is it secure and does it have metrics with logging?
- Did any unnecessary headers from the response?
- Is there at a minimum Authentication and ideally authorization when accessing the API?
- Is there logging of errors and incoming requests occurring?
- Has any sensitive data (PII) used to train the model, provide context to the model, or be passed to the model via chat been cleared with the data protection officer or a similar authority? (regulation varies by jurisdiction and type of data)
Additional FastAPI Resources
FastAPI: Modern Python Web Development by Bill Lubanovic
- This book covers everything you need to build an API from the ground up using FastAPI. Important points in this book to pay attention to are security and performance. Not securing your API that wraps Ollama can leave your data that was feed into the model as context being exposed and leaves it vulernable cause Denial of Service(DOS) attacks.
- Lubanovic does a good job covering FastAPI and provides an abundance of resources but for those who want to expedite deploying Ollama and FastAPI there are 3 chapters that are the most relevant. Chapter 3 & 4 cover more details about getting started with Fast API and implementing concurrency and Asynchronous operations. Chapter 13 is most relevant as it covers deploying to production including setting up multiple servers to balance load and containerization with Docker.
- This is the documentation page for the FastAPI project. In most cases this is should be the first place to start troubleshooting and for finding the reference for a class you want to use.
Additional Ollama Resources
- Ollama documentation
- This is a link to the ollama/docs folder in the Ollama main branch on Gihub. For Ollama this is the reference for functionality and updates to parameters.
- Diving Into DeepSeek: Running DeepSeek Locally using Ollama
Reference Page Link- This is a beginner friendly hands-on practical book I wrote on the process of setting up Ollama and running a DeepSeek model,deepseek-r1:1.5b the same model as in the examples above.
Additonal Posts
Following this post, I wrote a series to build off this foundation. Link